Musing about semantics in BI
Recently I've been blogging mostly about SAP's new HANA product and the general in-memory approach. My deeper professional focus is a little further from the metal, in datawarehousing, business intelligence, and planning processes and architectures. Some recent emails, tweets, and discussions have prompted me to get back to my roots ... but roots are hidden and hard to conceptualize. So I brought diagrams!
One of the hard problems in datawarehousing and business intelligence is semantics, or meaning. We need to integrate the semantics in user requirements with the semantics of the underlying systems. We need to integrate the semantics of underlying systems with each other. And we need to integrate the semantics of a system with itself!
That wasn't very clear. Here's an example: Revenue.
Simple right? Not so fast!
Our users want a revenue report. When our finance users say revenue, they might mean the price on the invoice, without any discounts. But our ERP system may display revenue as a number that includes certain types of discounts. (This is the problem of integrating user's semantics with system semantics.) And our other ERP system may include a different mix of discounts in the revenue number. (The problem of integrating the semantics of underlying systems with each other.) Meanwhile, a single SAP ERP system will record revenue from a sales in several different places: On the invoice, in the G/L, maybe in a CO-PA document. Each of these records is going to have a different semantics and it's quite possible that it is difficult to derive the number the system displays to us from the data in the underlying tables. (The challenge of integrating the semantics of systems with themselves.)
Wow! That's just the first line of the P&L statement!
This example is a little contrived, but it's not too far from the truth. At this point, I just want to recognize that this is a tough problem and we really don't have a very good solution to it aside from the application of large amounts of effort. The interesting question to me right now is where this effort is already embedded into our systems (so we don't have to expend as much effort in our implementations) and what affect SAP's new analytics architectures might have in this area.
I promised diagrams and musing, so here we go. I want to talk a little bit about layering semantic representations on top of ERP data models, which tend to be highly optimized for performance and therefore quite semantically opaque. In order to think more clearly about the different ways of doing this and the trade-offs involved, I cooked up some pictures. We'll start simple and move on to more complex architectures.
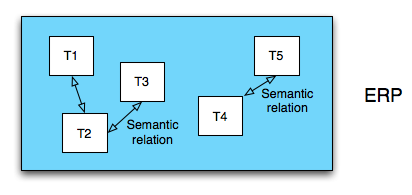
This is a naive model of an ERP system. It's got a lot of tables: 5 (multiply by at least 1000 for a real ERP system). These tables have a lot of semantic relationships between themselves that the ERP system keeps track of. It knows which tables hold document headers and which tables hold the line items for those documents. It knows about all the customers, and the current addresses of those customers, and it knows how to do the temporal join to figure out what the addresses of all our customers was in the middle of last year. I don't have much more to say about this. It just is how it is: Complicated
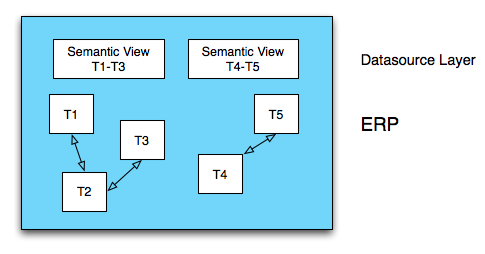
This is an ERP system that has semantic views built into it. These views turn the underlying tables into something that makes sense to us - we might call them views of business objects. Maybe the first view is all of those customers with start and end dates for each address. And the second view might be our G/L entries with line item information properly joined to document header information.
Interestingly, creating semantic views like this is almost exactly what BW business content extractors do. These extractors have been built up over more than a decade of development. They were built by the application teams, so if anyone knows how the application tables are supposed to fit together, it's the people who built these extractors. There is a lot not to like about various business content extractors but we can't deny the huge amount of semantic knowledge and integration work embedded in these tools.
Other tools, like the BusinessObjects Rapidmart solutions also know how to create semantic views of underlying ERP tables, though Rapidmarts accomplish this in a slightly different way. There is a lot of knowledge and work embedded in these solutions as well.
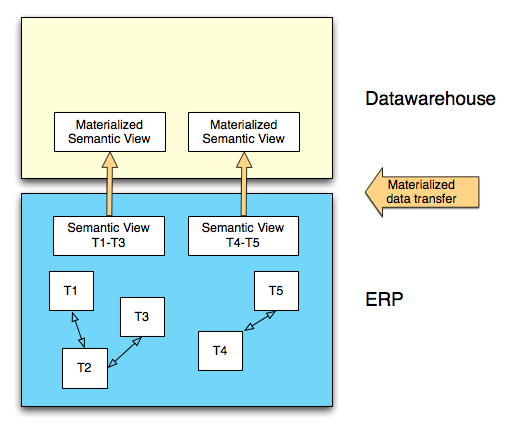
When we use the business content extractors with BW, we move the semantic view that the ERP system creates into a structure in the datawarehouse. As long as you use the business content extractors you don't need to worry much about the ERP data models. This diagram shows a fairly traditional datawarehousing approach. The same sort of thing happens with other solutions based on semantic representations of ERP data.
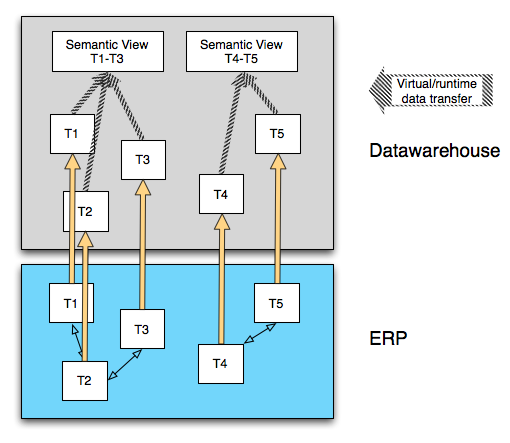
Another option is to directly replicate our ERP tables into an analytic layer. This is what happens in the case of SAP HANA if you are using Sybase Replication Server to load data into HANA. Notice the virtual semantic views that are created in the datawarehouse system. This work must be done for most ERP data structures, because as we've already discussed, these ERP data structures don't necessarily make any sense on their own. Creating these views is one thing we have been hearing from Vitaliy Rudnytskiy that IC Studio will be used for. Ingo Hilgefort touches on some of the same points in his blog on the HANA architecture. And Brian Wood also briefly touches on his role in developing semantic views for ERP data in HANA in his TechEd 2010 presentation.
I find that there are two interesting things about this approach, and these are things to watch out for if you are implementing a system like this:
First, whereas the semantic views in the previous diagram are materialized (meaning pre-calculated), these views are not, meaning that they need to be calculated at query run-time. Even on a system as blazing fast as HANA, I can see the possibility of this turning into a problem for certain types of joins. No matter how fast you are going, some things just take time. Vitaliy, again, does a great job of discussing this in his comment on Arun's blog musing on the disruption that HANA may cause to the datawarehousing space: http://www.sdn.sap.com/irj/scn/weblogs?blog=/pub/wlg/22570.
The second musing I have is that until SAP or partners start releasing semantic integration content, each customer or systems integrator is going to need to come up with their own strategy for building these semantic views. In some cases this is trivial and it's going to be tough to get wrong, but in a lot of cases the semantics of ERP tables are extremely complex and there will be lots of mistakes made. It is going to take a while for semantic content to reach a usable level, and it will take years and years for it to reach the level of the current business content extractors. Customers who are used to using these extractors with their BW installations should take note of this additional effort.
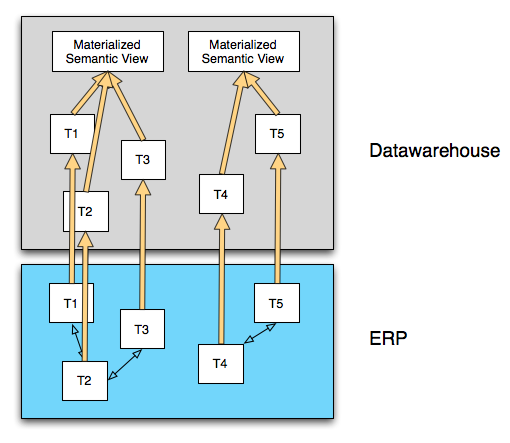
The solution to semantic views that are too processing intensive to run in the context of a query is to materialize the view. It is unclear to me whether or not you can use IC Studio to do this in HANA. At worst you can use BusinessObjects Data Integrator to stage data into a materialized semantic view, then query on this view in HANA. Of course, now we are storing data twice in HANA, and these blades aren't exactly cheap!
When we do this, using the tools currently available to us in HANA, we also lose the concept of real time. This is because our ETL process is no longer only a push process using Sybase Replication Server; now there is also a batch ETL process that populates the materialized view. We are back in the same trade-off between load-time complexity and query-time complexity that we face and struggle with in any BI system.
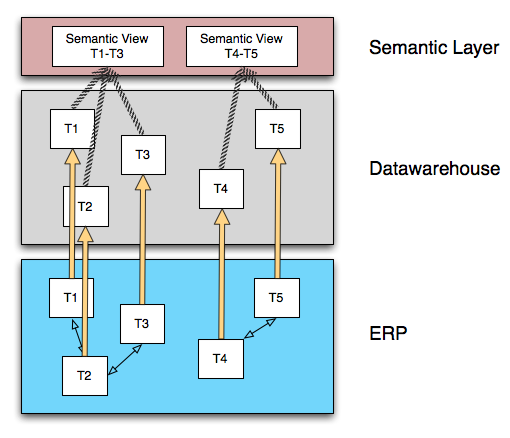
One possible solution to the second problem mentioned above (the difficulty of building semantic views on very complex and heterogeneous data models), is for SAP and partners to deliver semantic integration logic in a specialized semantic unification layer. We might call this layer the Semantic Layer, which Jon Reed, Vijay Vijayasankar, and Greg Myers discuss very insightfully in this podcast: http://www.jonerp.com/content/view/380/33/. I suspect that this layer will be a central piece in the strategy to address the semantic integration problem that is introduced when we bypass the business content extractors or source datawarehouse structures from non-SAP systems.
This is even possible across source systems in BusinessObjects 4.0 with the use of Universes that support multiple sources, a feature that is new to this release. It is a very powerful idea and I really look forward to seeing what SAP, customers, and partners build on this new platform.
But I'm a little worried about this approach in the context of higher-volume data, and the reason is those stripped arrows crossing the gap between the datawarehouse system and the semantic layer system. If you look back at the previous diagrams, the initial semantic view is always in the same physical system as the tables that the semantic view is based on. Except in the last diagram. In this diagram the semantic view is built on a different platform than the data is stored in.
What does this mean? It means for certain types of view logic, we are going to be in one of two situations: Either we are going to need to transfer the entire contents of all tables that feed the view into the semantic layer, or we are going to need to do large numbers of round-trip queries between the semantic layer and the datawarehouse layer as the semantic layer works to incrementally build up the view requested by the query. Either of these integration patterns is very difficult to manage from a performance perspective, especially when the integration is over a network between two separate systems.
There are ways around this, including (re)introducing the ability to easily move semantically integrated data from an ERP system into a hypothetical future HANA datawarehouse, or tight integration of the semantic layer and the datawarehouse layer that allows the logic in the semantic layer to be pushed down into the datawarehouse layer.
I wonder if we'll see one or both of these approaches soon. Or maybe something different and even better!